 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTechnology Readiness Levels for Machine Learning Systems
Jan 11, 2021

The development and deployment of machine learning (ML) systems can be executed easily with modern tools, but the process is typically rushed and means-to-an-end. The lack of diligence can lead to technical debt, scope creep and misaligned objectives, model misuse and failures, and expensive consequences. Engineering systems, on the other hand, follow well-defined processes and testing standards to streamline development for high-quality, reliable results. The extreme is spacecraft systems, where mission critical measures and robustness are ingrained in the development process. Drawing on experience in both spacecraft engineering and ML (from research through product across domain areas), we have developed a proven systems engineering approach for machine learning development and deployment. Our "Machine Learning Technology Readiness Levels" (MLTRL) framework defines a principled process to ensure robust, reliable, and responsible systems while being streamlined for ML workflows, including key distinctions from traditional software engineering. Even more, MLTRL defines a lingua franca for people across teams and organizations to work collaboratively on artificial intelligence and machine learning technologies. Here we describe the framework and elucidate it with several real world use-cases of developing ML methods from basic research through productization and deployment, in areas such as medical diagnostics, consumer computer vision, satellite imagery, and particle physics.
Scalable Pooled Time Series of Big Video Data from the Deep Web
Oct 21, 2016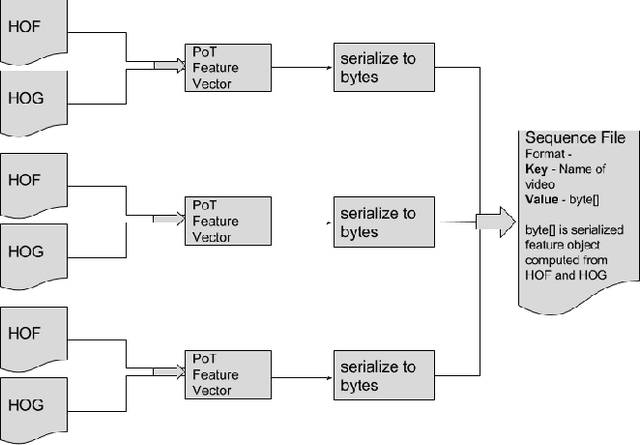
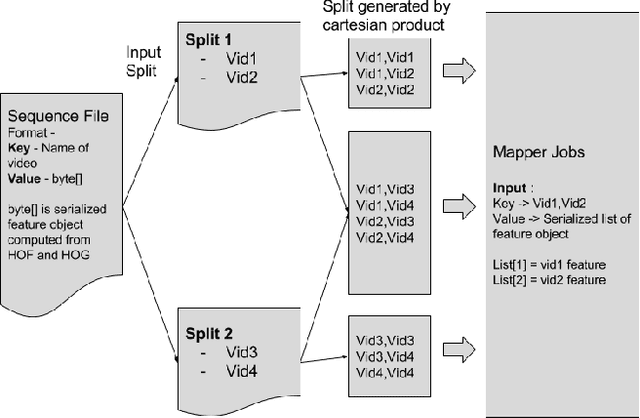

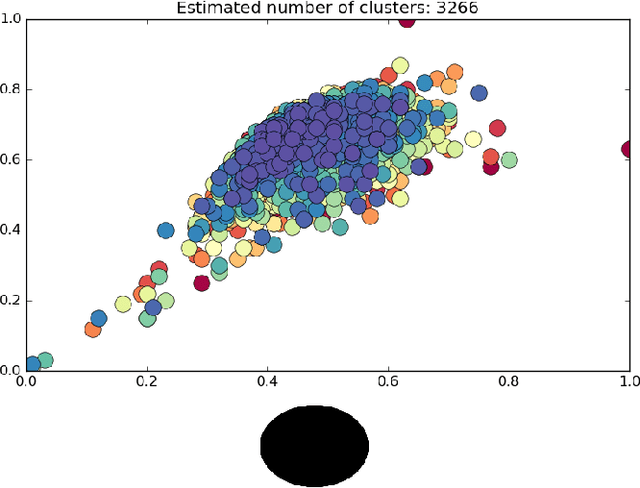
We contribute a scalable implementation of Ryoo et al's Pooled Time Series algorithm from CVPR 2015. The updated algorithm has been evaluated on a large and diverse dataset of approximately 6800 videos collected from a crawl of the deep web related to human trafficking on DARPA's MEMEX effort. We describe the properties of Pooled Time Series and the motivation for using it to relate videos collected from the deep web. We highlight issues that we found while running Pooled Time Series on larger datasets and discuss solutions for those issues. Our solution centers are re-imagining Pooled Time Series as a Hadoop-based algorithm in which we compute portions of the eventual solution in parallel on large commodity clusters. We demonstrate that our new Hadoop-based algorithm works well on the 6800 video dataset and shares all of the properties described in the CVPR 2015 paper. We suggest avenues of future work in the project.
Ensemble Maximum Entropy Classification and Linear Regression for Author Age Prediction
Oct 04, 2016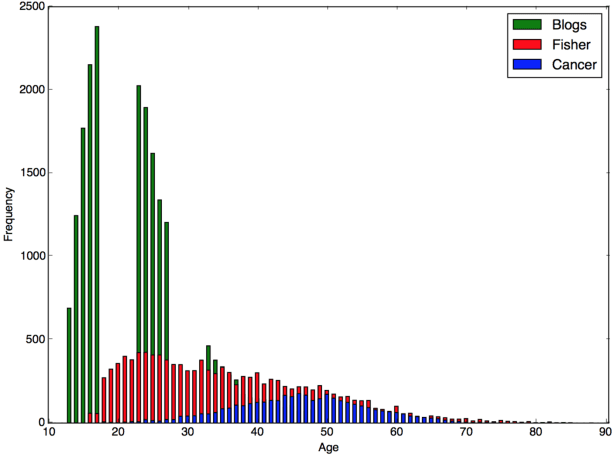
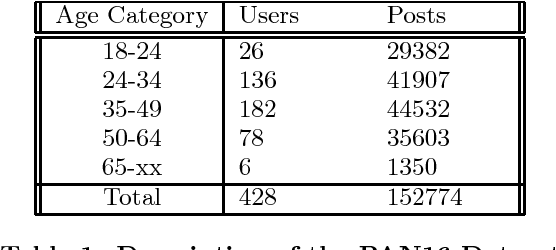
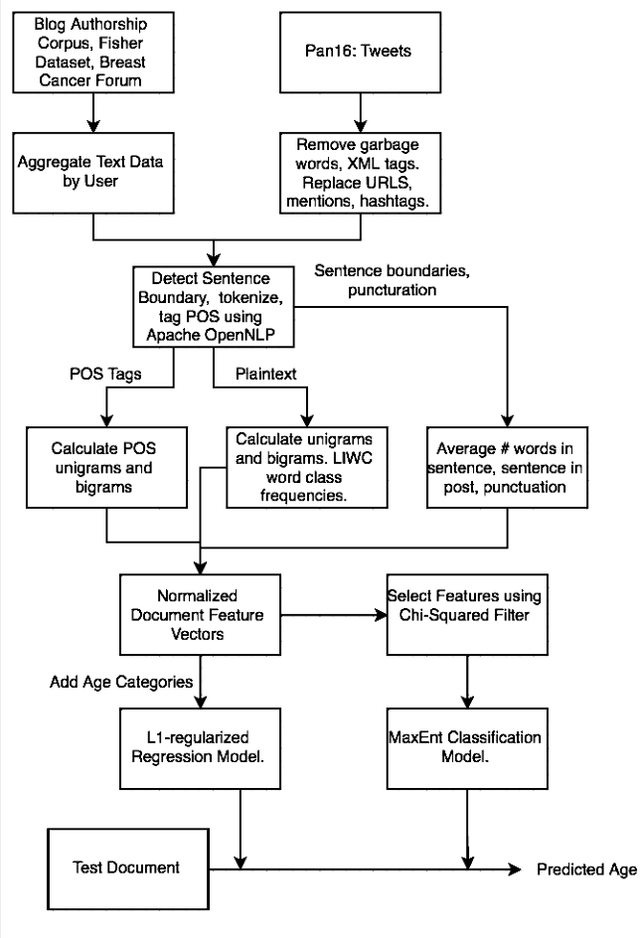
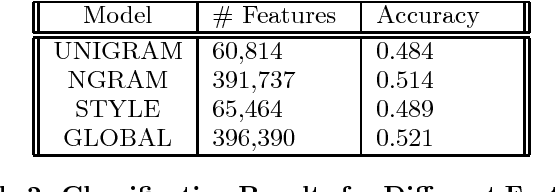
The evolution of the internet has created an abundance of unstructured data on the web, a significant part of which is textual. The task of author profiling seeks to find the demographics of people solely from their linguistic and content-based features in text. The ability to describe traits of authors clearly has applications in fields such as security and forensics, as well as marketing. Instead of seeing age as just a classification problem, we also frame age as a regression one, but use an ensemble chain method that incorporates the power of both classification and regression to learn the authors exact age.